Some of these are why I bail for a “real language” in many seemingly simple scenarios.
As soon as I care about datetimes, it’s just easier to use stat() and a proper datetime API.
I can treat filenames as byte arrays and translate to Unicode or let the language do it for me.
In dire circumstances, find … -print0 | xargs -0 second_script is usually my fallback, but that has pitfalls as well.
Go has been a blessing there for me, not having to rely on a runtime across diverse hosts. But that’s a preference and doesn’t help on old kernels w/o epoll().
So many battle scars from inconsistency in Bash and GNU utilities over the years, especially on Unixes’ bundled versions (Solaris, etc) or supporting GNU, BSD, SysV, and HP-UX in the same script. Used to deploy a ksh88(ish) on all for SOME consistency.
Luckily now I’m not supporting anything but Linux anymore. When I can’t Go, then I just hijack some tool’s bundled Ruby (eg Puppet), Python, etc when I have to handle that and stick to the standard library.
I am too lazy to C these days like I used to. I’m usually dealing with an emergency (looking at you log4j) and don’t have the cycles to cover the gotchas there.
Why in the world does Unix allow newlines in a filename in the first place? That's just such an obviously brain-damaged idea. There's not a single rational use case for it, yet it breaks nearly every text-based tool you could possibly imagine...
Why would Unix go and add random restrictions to filenames?
And what text protocol requires you to just insert user data without escaping or re-encoding? That looks badly broken. The kind of broken that will give your entire system to a hacker for encrypting and demanding ransom.
> yet it breaks nearly every text-based tool you could possibly imagine
It breaks badly designed text protocols - some can argue that it's a good idea - "crash early, crash loud" etc.
Also if your protocol breaks with newlines, it probably breaks with other non-literals - brackets, quotes, NUL-bytes, control characters, carriage return char, multibyte chars etc etc.
> It breaks badly designed text protocols - some can argue that it's a good idea - "crash early, crash loud" etc
This is decisively not a case of "fail loudly", which I agree is generally a good idea. The very first example in the article is one of silent incorrect/ambiguous output, not loud failure.
I'm against limiting the character set allowed for file names. macOS is also in the same boat with Linux, going one step forward and allowing \null terminator even in the filenames.
If we're going to limit filenames' character sets, I can offer a simpler solution:
Why allow file names? OS should provide a UUID for all files. No names, nothing. We can just write which file is what to another file, noting its UUIDs to sticky notes.
> Why allow file names? OS should provide a UUID for all files. No names, nothing. We can just write which file is what to another file, noting its UUIDs to sticky notes.
But... isn't that what filesystems, in effect, already do? Files have IDs, which are mapped to names in a separate record. Having it in one common shared place for the whole filesystem, and a common OS API that provides access to it for all mounted filesystems, just makes things like useful, user-friendly shells (graphical and text), and common controls possible without everything user-facing needed separate UI constructed from scratch for each apps files.
This is an old solution to a problem that does not exist. Yes, in that case the file system can be a key-value store. It would eliminate the need for a tree structure. But the tree structure has a meaning: it adds context. The directories are containers of files that adds a semantic abstraction to the files within.
Why do we impose hierarchy so much in file systems? We already allow hard and soft links, so it’s not even a tree anyways. Why not just allow any reference types you want; no name with extensions, but a set of tags. Why not identify files the same way a graph database query identifies nodes?
Because hierarchical structures and names are easy to explain to most people. macOS has supported tagging for ages, but I’ve never seen it used extensively or as a complete alternative to tree structure.
> Why allow file names? OS should provide a UUID for all files. No names, nothing.
On an application level that's sort-of starting happen. It's annoying though. Sometimes you just need to know where the actual F Apple put your photo's (it's not obvious). If different applications need to work with the same files, then there's an annoying coordination problem if one application tries to pretend that "files" don't exist and another needs a file path.
Autodesk Fusion 360 tucks your projects into a cloud. I know there's some local cache, but there's no need to think about it because only Fusion-360 handles those "files" and I just worry about my project assets as presented to me by the UI. In that case, it's OK, but it also suggests a "walled-garden" of files for each application.
We could use SHA-256 for the UUIDs, map names to hashes in special directory files, and build a source code control system out of it too while we’re at it.
Unix filenames are just sequences of bytes, not defined as strings. Most programs parse them as utf-8, but there is nothing mandating that. Obviously that leads to problems.
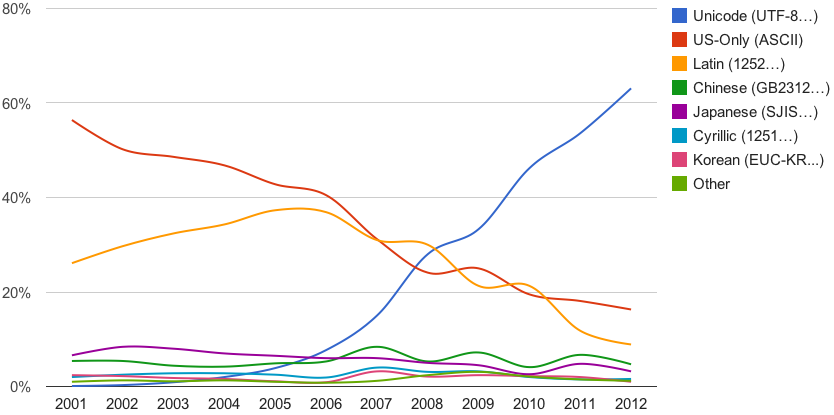
> This actually rules out nearly any non-UTF8 character set (besides ASCII.)
It doesn't--pretty much any character set that has seen widespread use in the past few decades would be compatible. Any single-byte charsets that are ASCII compatible (such as most Windows CP* sets or the entire ISO-8859-* suite) would work. Most Asiatic charsets (e.g., EUC-JP, Shift-JIS, Big5, GBK) that use variable-width encodings follow the rule that characters in the 0x00-0x7f range are ASCII and subsequent characters in the 0x40-0xff range, and so are themselves compatible as well.
So actually the list of notable incompatible charsets is easier to write out: UTF-16, UTF-32, EBCDIC, and ISO-2022-* charsets (which are mode-switching).
Eh, fair enough. While you’re correct, character sets that are “ascii, but something custom when the high bit is 1” are all just “ascii” to me, in that they are all mutually incompatible for anything other than the first 127 characters, and 8-bit encoding in general has been ubiquitous for nearly as long as ascii has been defined. (Meaning that when most people say “ascii”, they’re actually referring to one of those encodings in practice.)
Asiatic character sets are an interesting point though. I wonder how common they were at the time of what Linus wrote…
> While you’re correct, character sets that are “ascii, but something custom when the high bit is 1” are all just “ascii” to me
Don't call them just "ASCII"--that only serves to confuse people. Call them 8-bit ASCII-compatible charsets if you need a collective noun, but note that they are very different.
> (Meaning that when most people say “ascii”, they’re actually referring to one of those encodings in practice.)
Having actually worked on charset handling, when most people say "ASCII", they mean "ASCII" and not anything else. If a document is labeled as ASCII, then generally it should be handled as Windows-1252. If a conversion function claims to convert ASCII to something else, and doesn't provide any error mechanism (which it really should), then it usually means ISO-8859-1 aka Latin-1 aka map each byte to the first 256 Unicode characters.
But I'd never see, e.g., a KOI8-R document referred to as ASCII, nor anything that claimed to be ASCII assumed to be a KOI8-R document.
> Asiatic character sets are an interesting point though. I wonder how common they were at the time of what Linus wrote…
At the time he wrote that, the main Asiatic charsets for Chinese and Japanese would have been more common than UTF-8. Maybe Korean as well, although Linus's message is around the time that UTF-8 overtook EUC-KR. In any case, anyone who knew anything about character sets at the time would have been well aware of Asiatic variable-width character sets.
I appreciate your insight, but I just want to expand on one point:
> Having actually worked on charset handling, when most people say "ASCII", they mean "ASCII" and not anything else.
Approximately zero people are referring to a true, packed, 7-bit encoding when they say "ASCII". They're nearly always talking about an 8-bit character set, and in such cases, something must happen when the high bit is 1. (I've never seen one that plain ignores or uses error glyphs for characters >127, although you likely have more experience with this than I do.) This is why I said people are referring to one of these encodings in practice... because ascii is 7-bit, and approximately everyone is talking about some 8-bit encoding of one form or another.
I would definitely agree that most wouldn't call KO18-R "ascii", but they may use the term "ascii" to describe the first 128 characters of KO18-R. (Notwithstanding if it uses weird replacement characters like Shift_JIS does with the backslash and the yen sign.) This is the reason for my comment about how the weird "ascii + custom" all just feels like ascii to me... if you stay below 128 it literally is.
I'll modify my original statement thusly:
> This actually rules out nearly any character set that isn't compatible with ASCII.
And add an addendum that if you don't use UTF-8, you can't use unicode and will be stuck in code page/locale hell.
> I've never seen one that plain ignores or uses error glyphs for characters >127
Reporting an error is the default behavior if you try to decode such a string with the ASCII codec in Python and .NET, at the very least.
The first 128 characters of KOI8-R are, of course, ASCII (the "weird replacement characters" are, in fact, explicitly allowed!). But a file encoded in KOI8-R is only ASCII if it contains those first 128 chars.
> if you don't use UTF-8, you can't use unicode and will be stuck in code page/locale hell.
UTF-7 was a thing. It just turned out that nobody really needed it.
Why not also, while at it, disallow spaces too? They can very easily cause problems too, if you split by spaces instead of newlines. Quotes and backslashes obviously are also bad. How about all of non-ASCII unicode? That'd break all code assuming character count equals byte count, and can probably cause buffer overflows when people count correctly.
Any characters you disallow still allows people to fail on some other character. Sure, it'd decrease the likelihood of messing things up by some amount, but that's a half-assed solution at best, and would make people check for mistakes less at worst. Imagine if intel fixed the pentium FDIV bug by only fixing 30% of the wrong results.
I can’t think of why you’d ever want a newline in a filename, but it does make for easier reasoning about what characters (or perhaps I should say bytes) could be found in filenames, as opposed to having to remember a long list of exceptions.
> That's just such an obviously brain-damaged idea.
Is it, though? "Every character except '/' because it's the directory delimiter" seems pretty straight forward to me...
> There's not a single rational use case for it, yet it breaks nearly every text-based tool you could possibly imagine...
You don't have a use case, but that doesn't mean nobody else has one.
And as far as "text-based tools" go, their developers should RTFM. I'm fairly sure UNIX existed before almost all of them, and it's accepted new lines all along.
It is odd. Though tools like find have "-print0" for this purpose. And corresponding input flags for xargs, perl, sort, uniq, cut, head, etc, that accept NUL terminated vs newline terminated lists.
No, write your software properly. Assuming anything at all about file names is how we get to silly things like Windows' "CON" or whatever restrictions.
my imagined reason is -- because when that terrible day happens, and an important file with some new name, does in fact get a newline in it, the rest of the system now has predictable code paths. Q. Is this related to perl, who knows
This is one reason Perl was very popular even before CGI was a thing. You could get to things like stat() with an interpreted language that was very portable. It also has the "-0" flag to accept the null terminated output of "find -print0".
Greg aka graycat was a real IRC legend 20 years ago. I learned so much from him.
Many a happy hour did I watch him flaming lazy newcomers looking for a quick fix in #debian, right about the time when Linux as a commercially viable server platform was taking off.
Almost every admonishment was accompanied by sound technical advice which was useful to lurkers as well as the unfortunate noob who dared ask.
Greg Wooledge's bash wiki is my goto resource for bash scripting. Everything I always need to find out is in there (Bash Guide + FAQ). I didn't know about his IRC persona which only improves my appreciation of him, so thanks for sharing.
More importantly, we need to get rid of the ability to put line feeds, tabs in file names and also disallow odd starting characters such as tab, dash and $
I wish someone would add a mount option for that and have eg fedora be a trailblazer to fix the few apps that break
Nah.. we need to use object graphs as streams instead of whitespace "(un)parsable" text. The output to the console (ui) or gui (ui) can be different, but the data should be structured
Sounds like Powershell to me. I'm down, as long as the syntax is as simple and terse as on UNIX-based systems and not what Microsoft did (were they paid by the character for flag names?)
They could at least change the names order and start with the specific part (TrustAuthorityKeyProviderClientCertificateCSR-Get), so the (braindead) MS version of tab completion would be useful.
Amusingly HN cuts off the end of the command you typed, I assume using css overflow attributes (don't have an easy way to tell on my UA). I assume it stops at "cate"[0]. I see this sort of chopping a lot, which naturally makes sharing PS commands frustrating -- although there may be workarounds like using `backticks`.
0: Nope, had to paste it to see it ends with "cateCSR".
That is basically integrations, there is never going to be nice integrations to my Cobol mainframe linked to a Springboot fuzzbuzz. As is stated in other comments the big issue is usually about being cross platform, and that is a subset of the ls problem: Most of the time you have control over your inputs, until you haven't. This is true for every language even Python which is obnoxious about that. What I mean is that you will always hit edgecases in integrations and you never have time to write new ones.
I always felt that powershell was tab unfriendly, the Get- prefix is hard to get used to. I may be wrong that they have a good way to deal with one-off integrations in a sane manner.
Powershell is usually terse enough as one uses aliases for interactive? (Not to mention tab completion)
E.g list files
Shell: “ls”
Powershell: “ls”
Show sizes of files in size order
Poweshell:
ls | sort length | select length
in Unix:
find -maxdepth 1 -type f -printf '%s\n' | sort - n
Lovely.
I use the long form stuff for scripting in Powershell (tab completed in the editor) but it’s not like anyone writes “Get-ChildItem” instead of dir/ls/gci.
This can work with something like nushell, but obviously breaks the entire current universe of coreutils.
In the normal world we can solve this problem without breaking everything by adding --jsonout or similar to all the coreutils and then we can have sanity by piping to jq.
> This can work with something like nushell, but obviously breaks the entire current universe of coreutils
Good, because these utilities suck. Half of them only exists because the data is unstructured in the first place, the other half are mostly made of parameters that only exist for the same reason, and most of their names have no apparent relation to what they do. It is time to move out of the 1970s.
Hi. Author of Next Generation Shell here. Totally agree. Also UI of the shell is stuck and ignores pretty much everything that happened in last decades.
Not necessarily though, as filenames aren't required to be valid strings, so that would break json syntax. And json doesn't have a syntax for "just a blob of bytes", besides the fact that wrapping bytes in text just to be decoded back to bytes seems silly to me, but that's an opinion
If you do this, this will break every program which takes text based filenames on command line.. which is most of ghem. It is an interesting idea, but I don't think it would be Unix anymore.
'Unix' is too low level anyway.. Unix is about reading/writing byte streams..
I don't think the "interactive shell" was meant for scripting anyway. It's like writing your scripts in selenium similar tools. Someone only needs to change the structure or order of the webpage, and you have a problem, depending on how you do your scraping / interacting with the output.
I dont think unix was every truly about byte streams.
Make each program do one thing well. To do a new job, build afresh rather than complicate old programs by adding new "features".
Is the core point. Later editions went on to specify text as the preferred language for these programs to communicate in but I don't think that's key to upholding the unix philosophy. It was just the easiest to work with at the time
We just need to agree upon a common framework for these programs to communicate with. There will definitely be a lot of churn though
> Make each program do one thing well. To do a new job, build afresh rather than complicate old programs by adding new "features".
That's a quote from '78, by the Doug McIlroy, the inventor of Unix pipes. Pipes are exactly that... reading and writing bytestreams.
Also him:
- (ii) Expect the output of every program to become the input to another, as yet unknown, program. Don't clutter output with extraneous information. Avoid stringently columnar or binary input formats. Don't insist on interactive input.
Later:
Write programs that do one thing and do it well. Write programs to work together. Write programs to handle text streams, because that is a universal interface.
This only happens because people are scripting in their ui. They shouldn't. "Unix admins" laugh at people who do the exact same things within office or other GUI solutions.
Using "text streams".. yes, for performance, a stream is better. Same with SAX vs DOM. nobody likes SAX
graphs aren't streams. You could, of course, serialize an object graph to a stream (such as by reducing it to linear text representation of the objects with IDs and links.)
Why? The name of a file is none of the filesystem’s business. If users choose names that make using software difficult it’s on them. It’s not like there aren’t ways to handle any kind of “weird” character in a file name, as the linked article states.
Furthermore, if the kernel/filesystem starts prohibiting certain characters this is more code to maintain and test. User space programs that previously worked fine will stop working. All of this just to prevent someone shootings themselves in the foot by misunderstanding how filenames should be manipulated.
If you’re looking at file system in the purist possible sense, you’d be right. But equally a lot of other meta data is stored beyond the inode that file systems “understand”. And there is already precedence of file systems having code to intelligently handle file names (eg options for case sensitivity). So pragmatically it’s not an unreasonable suggestion to house any code defining legal file names in the file system driver too.
The biggest argument against that in my view isn’t down to testing but DRY methodologies: if the code sits in the kernel then it should work against all file systems and not just supported ones.
In practical reality, the name of the file is the filesystem's business. It would be nice if it operated similar to cloud filesystems, where you could version based on GUID that is disconnected from the filename, but the practical reality is that users and developers have long accepted the local operational mode.
I already can’t use NUL and slashes in a file name. And win32 limits me even more. It’s always been a compromise
And the amount of feet that have been shot by weird file names is staggering.
Programs will stop working, but that’s why we need a bleeding edge distribution to find them. In the short term things will break, in the long term quality will increase. Just like memory protection broke some DOS apps in the short term
I hope you won't be in the position of handling the non-ascii file names. Whitespaces, symbols and other complicated glyphs are widely used in file name since Windows 95.
-b, --escape
print C-style escapes for nongraphic characters
I'd also add:
-1 list one file per line. Avoid '\n' with -q or -b
to make sure you can easily split the list by just the EOL, in case for some reason it thinks it is talking to a terminal and tries for format things for a human.
It would be trivial to code but any such wrapper would add overhead to file system operations. FUSE is a fantastic set of APIs (I’ve used it personally) and performs remarkably well considering it is constantly swapping memory between kernel and user space but for wide spread adoption any feature like this would need to be part of the native file system options.
And how would that be even remotely useful? Unless something changed recently, FUSE has so much overhead it's only useful for niche applications and prototyping.
A thousand times this. There is absolutely no reason to allow newlines in filenames, and it is pathetic that there isn't even yet a mount option to disallow totally idiotic filenames (at the minimum I don't want programs to create filenames with newlines or invalid utf-8).
It's great that file names in the user/kernel ABI are treated as unstructured NUL terminated byte streams so I can do what I want with my file names even if you don't like it. And you can do what you want with yours, including not creating ones you think are idiotic, or using filesystems with code or options that restrict what names can be used.
Can you give a plausible use case? Filenames can't be arbitrary bytes anyway, since they cannot contain '\0' and '/'. What's a realistic example where it's really useful to be able to stuff arbitrary bytes into a filename, just not '/' or '\0' and where C or URL escaping would somehow be onerous enough to justify all the other problems these pathological filenames create?
Do you really think disallowing pathological filenames (at least as a mount option) would be more expensive than the countless security exploits allowing them has already caused or massive tax nearly all software that tries to deal with filenames robustly needs to pay for it?
Forget shell scripting, almost no software can afford to just pretend filenames are arbitrary bytes.
They typically still somehow need to be displayed to and be editable by end users somewhere along the line, and this means (in unix-based systems) some conversion to-and-from utf-8. Which is going to cause problems[1].
And even if you don't directly need to handle this yourself (but you do, even for a simple shell script or command-line utility or a library that wants to provide an error message with a filename), there is now a whole lot of extra bloat and complexity and edge cases no one handles in practice. With weirdo types like special filename strings, which are neither bytes or proper unicode like python's unicode surrogate encoding (which effectively leaks into all text handling). And of course different languages and eco-systems solve it differently (e.g. whereas python bends its general unicode string for this, Rust has a OsString).
[1] Even the utf-8 compatible subset causes problems of course. E.g. if you have a terminal program that needs to display untrusted filenames to an end user, you now have to deal with problems like terminal escape injection via filenames.
Compatibility. And a mount option seems fine if you don't need compatibility.
That does not relieve applications of the requirement to robustly handle paths and file names though.
> Forget shell scripting, almost no software can afford to just pretend filenames are arbitrary bytes.
Much non-script software can actually treat file names as arbitrary bytes and just pass them through its typical input and output mechanisms. Shells and terminals are very special classes of application, and they need a lot of I/O sanitization whether or not the filesystem restricts file names.
But is there any real use case for that? For me I've only encountered this when something else went wrong, I'd rather have an error at that time than later trying to find out what this garbage is and how to remove it.
> The kernel actually does "break compatibility" from time to time if there's no software relying on the behavior.
Certainly not something like this by default though.
To be clear, this wouldn't somehow solve shell / scripting / terminal issues with file names. There are many other special characters and escape sequences and other whitespace like spaces that can trip up incorrectly written programs. These can certainly not all be removed by the kernel so the incremental advantage of just filtering out a couple of such cases doesn't seem like it would be very big.
These all seem to be ls bugs. It's a common pattern when outputting data to format it such that the receiver can unambiguously separate the data from the formatting. If you use CR/LF in your output formatting, then those characters need to be escaped in the data. If your attacker can deceive you into printing fake output by crafting their filename as :
"\n -rw-r--r-- 1 user group 12 Dec 15:55 mostly_harmless_planet"
...then you have already lost.
Violating this pattern always leads to problems like format string vulnerabilities, SQL or executable injections etc. As the long history of fighting against these problems shows, "banning weird characters" without fixing the bugs will always lead to problems, some apparently harmless characters find devious uses etc. You can't unscramble eggs.
The only real solutions are properly escaping the payload so that it can be unambiguously interpreted. And you can't claim that the authors of 'ls' don't expect their output to be consumed by other programs.
Interestingly, ls does escape characters like \n in its output when it's printing to a terminal, but not when it's being piped into other programs. Try this by making a file with a newline in its name, and then comparing "ls" with "ls | cat".
I think "jc" stands for "jesus christ!" because I just exclaimed that out loud thinking about the amount of time I've wasted trying to parse dig outputs, or something similar. Spent a nontrivial amount of time looking for lightweight tools to convert the typical "fwf" of coreutils style programs.
Definitely running "pipx install jc" immediately (pipx is great for managing python-based executable programs, avoid the mess of venvs).
No. Powershell is a whole new CLI user land as well as a shell. If you want something that’s compatible with POSIX but still has smart pipelines and native support for JSON then you’re better off with Elvish or Murex as shells.
Parsing the textual output of ls is such a natural idiom that I'm happy to renounce any other thing that causes trouble. Give me a "-o sanenames" option for mount, instead.
If you're listing just the filenames, the things that makes fd fast (the parallelised directory traversal when you do something that requires stat calls or similar) are irrelevant, as the getdents() calls are going to be more affected by your buffer size.
So for the limited subset of tasks where you're ok with using a tool that might not be installed and need options that requires stat calls and the directories may be large enough, it might make a difference.
You probably want -name or -iname which match glob-like expressions against the filename (the "i" prefix means case insensitive).
If you really need regex you can use -regex or -iregex, but be aware that they match the entire path (so if you do "find ." you will be matching a string that starts with "./"
`echo *` has many of the downsides of ls (doesn't escape e.g. space in filenames) and additionally breaks on directories where the expansion fills the command line buffer.
EDIT: Also note that "find ..." is also not safe from all the quoting issues without "-print0" or equivalent options to make it separate the names with ASCII NUL rather than linefeed or otherwise taking steps to handle filenames with actual linefeeds in them.
The problem is not the backticks. They were just used as quote characters. The problem is that shell expansion doesn't escape the characters. E.g. this is a cut down output from my system now after I did a echo >'/tmp/ space ':
$ echo /tmp/*
/tmp/bspwm_0_0-socket /tmp/config-err-Q667kI /tmp/foolog /tmp/ space /tmp/...
Parse that output and you get a broken list of filenames.
(author here) Yes thanks, that is exactly the point!
As I point out at the end of the doc, coreutils ls actually started quoting the names in 2016. However the format is confusing for people who can't read 2 or 3 types of shell strings, and not that readable.
In contrast, QSN is simply Rust string literal syntax, which are a cleaned up version of C string literal syntax.
$ touch $'foo\nbar' 'dq"dq' "sq'sq" # create 3 files with newline, double quote, single quote
# coreutils is correct, though I'm not sure people will understand $'\n'
$ ls
'dq"dq' eggs 'foo'$'\n''bar' "sq'sq"
Pipe through cat mangles the name:
$ ls|cat
dq"dq
foo
bar
sq'sq
In Oil, write --qsn will ALWAYS give you 5 lines if you have 5 names, no matter what they are
I think it's important for something like QSN to be built into the shell, because quoting issues arise in many places, not just filenames and ls.
Although this makes me think that we should have the inverse of `printf %q` to parse the output of coreutils ls. Oil does implement printf %q, but most people don't know about it.
$ printf '%q\n' -- *
dq\"dq
$'foo\nbar'
sq\'sq
Again it is actually correct, but sort of a grab bag of formats derived from shell strings. QSN strings will be familiar to anyone using Python, Rust, etc. consistent with Oil's slogan: It's for Python and JavaScript users who avoid shell!
So printf %q and %b are inverses in bash, but this doesn't work in other shells. QSN can represent NUL bytes, which are illegal in filenames, but are useful elsewhere.
First example suggests that `ls` should not be used but `ls -l` - the same program author advises against in the title, but with a parameter - works as expected and in this case would not result in "you can't tell".
> The problem is that from the output of ls, neither you or the computer can tell what parts of it constitute a filename.
Computer does not use console output of ls(1) to determine the list of files. It's for the user. The computer can tell what is a file here.
The title could also be stricter with s/ls/"GNU coreutils ls"/g, too. I could not reproduce all the issues with FreeBSD's ls(1) under zsh.
> First example suggests that `ls` should not be used but `ls -l` - the same program author advises against in the title, but with a parameter - works as expected and in this case would not result in "you can't tell".
The first example is used to demonstrate the issue and to demonstrate that "-l" introduces other issues (inconsistent escaping).
> Computer does not use console output of ls(1) to determine the list of files. It's for the user. The computer can tell what is a file here.
But if you try to use the output of ls in a script to find filenames, the computer will be using ls to determine the list of files. Hence the advice not to do so.
> The title could also be stricter with s/ls/"GNU coreutils ls"/g, too. I could not reproduce all the issues with FreeBSD's ls(1) under zsh.
I think that just emphasises why you shouldn't, as it demonstrates you can't trust the output of ls to be consistent between systems either. If you are sure you'll never need to run your scripts on another system, you might not care, but when it's so easy to prevent this by e.g. using find with "-print0" or equivalent, it seems silly to not just unlearn the bad habit of using ls for this.
This is one of those things I always look out for in submissions at work (as bad as that may sound)
It's one of the easy ways to guarantee a process will run into an edge case eventually...
General rule of thumb: when possible, lean on shell features. Globbing, expansion, redirection. That replaces dozens of tools (eg: `seq`, `ls`, `cat`, and so on)
Another example (though less severe) that comes to mind: subshells to simply read (cat) a file.
Unless you're doing things at a ridiculous scale/pace, it doesn't usually matter - but redirection is 'cheaper'.
(Talking about cases where you care about nproc/nofile ulimits)
I wish I could contrive better examples. I feel like my ability to 'sniff' this kind of stuff out is usually what makes my best contributions at work, but without being in the moment... it's difficult.
xargs is a good one. That's usually an indication you need an array, even though I think they're 'fake' in BASH
Honestly, I've yet to hear a good reason not to just use Python for scripting that's any more complex than a series of commands. I resisted this for years, but one day realized I was only doing it because it felt intuitively right that scripts were simple extensions of the way one engages with the terminal interactively. I had to come to terms with the fact that the intuition gap is due to the fact that bash is so dang awful.
Sadly I'm still there. Largely because... I killed my development mojo as a kid. C/C++ and the early web crazes.
Nowadays I'll do most ad-hoc complex things with BASH... but at a certain point I tend to use Ansible. I guess one could say I indirectly write Python through Ansible/YAML :)
I have a bash alias that creates a random playlist of videos or music with ls. I noticed that sometimes there were duplicates in the list.
If I can't use ls, it's not going to be a one liner anymore, so I have to create a file, store it somewhere, assign execute privileges and link my alias to it. Much more complicated.
In a similar way, ftp's "dir" command is only for humans. Every ftp library that is for accessing ftp API for programs is only guessing what in the "dir" output is filename.
{kind=link}
As soon as I care about datetimes, it’s just easier to use stat() and a proper datetime API.
I can treat filenames as byte arrays and translate to Unicode or let the language do it for me.
In dire circumstances, find … -print0 | xargs -0 second_script is usually my fallback, but that has pitfalls as well.
Go has been a blessing there for me, not having to rely on a runtime across diverse hosts. But that’s a preference and doesn’t help on old kernels w/o epoll().
So many battle scars from inconsistency in Bash and GNU utilities over the years, especially on Unixes’ bundled versions (Solaris, etc) or supporting GNU, BSD, SysV, and HP-UX in the same script. Used to deploy a ksh88(ish) on all for SOME consistency.
Luckily now I’m not supporting anything but Linux anymore. When I can’t Go, then I just hijack some tool’s bundled Ruby (eg Puppet), Python, etc when I have to handle that and stick to the standard library.
I am too lazy to C these days like I used to. I’m usually dealing with an emergency (looking at you log4j) and don’t have the cycles to cover the gotchas there.